发布日期:2025-03-01 16:35 点击次数:165
“我甚而说悉数行业、悉数应用、悉数软件、悉数就业齐值得基于新式东谈主工智能时刻、基于AIGC各方面时刻因循、大模子因循重作念一遍……”
2023年4月中旬,张勇在阿里云峰会上如斯畅言。这番讲话的配景,恰是那时风头正劲的ChatGPT大言语模子。

▲2023年的阿里云峰会上,张勇一语成谶
张勇口中的“悉数行业、悉数应用、悉数软件”,当然也包含了那时正堕入表面和落地泥潭的智能驾驶意见。并非莫得企业对此摩拳擦掌,但是算力的制约却亦然不言而喻的。
以面前的视角看,OpenAI汲取“从东谈主类反馈中强化学习”熟谙步地,履行上颇有几分通俗大家戏谑那种“力大砖飞”的滋味。
通过堆砌多半算力不吝能耗去熟谙大模子,最终受益了能源企业,以及这种算力芯片供应商。直到DeepSeek-V3的横空出世。
与ChatGPT-4比较,DeepSeek-V3的熟谙历程,算力铺张仅前者的16%,履行成本仅557.6万好意思元,折合前者(7800万好意思元)的戋戋7%。但两个大模子在履行部署哄骗上,才智却是肖似的。

▲DeepSeek面前已成为中国AI时刻冒昧围堵和封闭的符号
站在2025年头这个时候节点,值此国内乃至全球智驾行业过问收束状态迎接纳官阶段的要津时刻,这是否意味着新的变数?
“迟到”的DeepSeek
延续自本(丨)第二个十年中期的自动驾驶时刻,还是明确了依赖深度神经鸠合(DNNs)来处理特定任务,如感知、推测和有蓄意等。这些系长入般汲取模块化遐想——每个模块厚爱措置一个特定的问题,举例物体检测、旅途有蓄意或速率截止。
这种架构的优点在于它允许工程师针对每一个子任务进行优化,况且便于调试和考据。雷同的逻辑也体当今智驾系统的传感器系统遐想上,而前述优点亦然少部分企业坚决反对激光雷达,一直宝石所谓“纯视觉道路”的根柢原因。
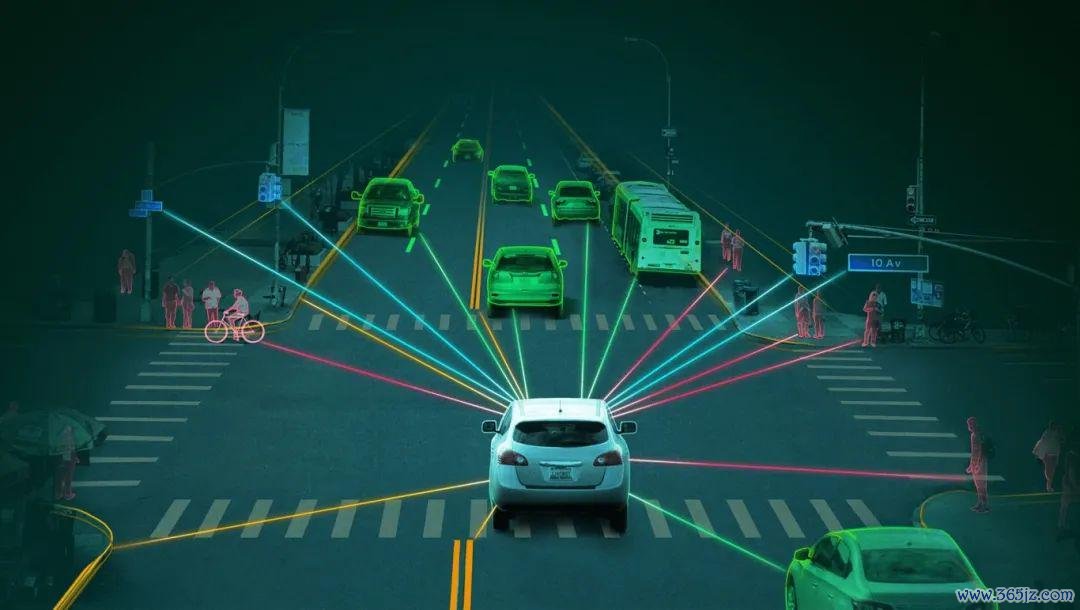
但是,跟着大模子——即使用Transformer架构构建的模子的流行,尤其是那些具有多半参数的大界限预熟谙模子,自动驾驶时刻迎来了新的可能性。
大模子的基本特色之一,是能够捕捉数据中的复杂模式,并通过大界限的数据集进行熟谙,从而在多种任务上展现出强劲的泛化才智,不错被用来增强系统的感知才智和决策制定历程。
在感知才智方面,能够充分和会与处理更复杂的图像、雷达和激光雷达数据,识别行东谈主、车辆、谈路标识等。传统多传感器和会所靠近的难题,在大模子面前赢得了很好地措置,而且不错擢升系统在极点天气或复杂路况下的鲁棒性。
此外,大模子在陆续学习才智方面的上风,这意味着其不错凭证新鸠合的数据不竭修订自身的性能,允洽不同的驾驶条款和环境变化。
更因为大模子明文摆设逻辑推导历程的特色,使得开导东谈主员在分析系统决策时,透澈告别了以往的黑箱状态。
通过透明化决策逻辑匡助调试和优化,并引入冗余系统和风险推测机制,确保在突发情况下的安全性。

▲2023年头ChatGPT的横空出世,不错被视为AI时刻的一次进攻冒昧。尽管其是一种“大言语模子”,但也启发了相邻的各赛谈
但是在2023年,ChatGPT的出世,并莫得立即对智驾行业带来特别的震荡。究其原因,如果以ChatGPT为模板来倒推的话,以Transformer架构把现存的智驾系统“重作念一遍”,从头熟谙的代价将会卓越宏大。
凭证由OpenAl团队发表于2020年的论文《LanguageModels日 are Few-Shot Learners》,熟谙一次1746亿参数的ChatGPT-3模子,需要的算力约为3640 PF-days。
英伟达配备80GB缓存的A100 GPU算力卡单卡的表面算力是 312TFLOPS,但磋商到tensor/pipeline parallel并行时刻算力利用率仅略越过一半,则完成一个月熟谙量需要接近千张80G内存规格A100算力卡。
而在2023年的时候,1000张80G A100的采购价钱大要1.5亿东谈主民币。

▲算力正成为现阶段发展AI时刻的要津,以及硬件上的主要瓶颈
DeepSeek之是以被视为紧要冒昧,乃是通过搀杂众人架构(MoE)与多头潜在珍爱力(MLA)机制,不但提高预熟谙中的算力利用率,还有用地虚拟了推理成本。
通俗淘气描摹大致可合计,是以OpenAI熟谙ChatGPT所需代价的五分之一,杀青了大致一样成果。
但是这一切发生在2024年末,成本密集投资智驾企业的契机窗口还是关闭,甚而通盘阛阓也被初步平分。
淘汰赛,还是启动。
收官阶段还是运行
几天前,也曾被誉为国内智能驾驶第一股的图森改日,在客岁初文书更正文娱以及影视制作赛谈之后,终究是莫得能够扛住压力,企业因为“内耗”而驱散。
东谈主去楼空,只余一地鸡毛。
往前推,在这个春节长假刚结果那会儿,2024年末已文书过问“低功耗模式”的纵目科技,也传出东谈主去楼空的音讯。
而只是两年半之前,这家企业曾一度因为拿下/7智能停车措置决策订单,一时成为行业幽闲标焦点。
往前讲究,客岁的11月27日,奏凯登陆好意思国的小马智行在首个交游日即跌破刊行价。尽管这家企业在国内也曾有过“行业独角兽”的光环,但在好意思誉之下却是企业自2016年建造以来,还是一语气圆寂八年的事实。履行此番上市,若干也有点终末一搏的滋味。

▲也曾,图森改日堪称国内“智驾第一股”
亦然在客岁的年末,也曾赢得过长城汽车轻易支持的毫末智行,也传出了裁人的音讯。而如果讲究到2024年的年头,即是图森改日从好意思股退市的大新闻——其市值最高时,也曾达到160亿好意思元界限。
在2023年末,国内智驾行业有了所谓“地大华魔”的说法。况且在客岁年末的时候,又进一步完善为头部供应商的“华元魔地面”,外加自研整车厂的“蔚小理极米”之说。
在这个大趋势下,DeepSeek的崛起如同给这股变革的波澜注入了强劲的能源。在熟谙遵守方面,经过其优化能进一步裁汰推理反馈时候。
这意味着在履行的智驾场景中,车辆关于各式复杂路况的判断和决策速率会大大提高。
举例,当车辆在高速行驶中一忽儿遭遇前列有难得物或者车辆变谈时,能够更速即地作出反应,幸免事故的发生。
另外,在数据标注这个步调,DeepSeek通过其专有的跨模态移动才智,有用地虚拟了熟谙历程中对东谈主工数据标注的依赖。

▲在行业头部,马太效应还是出现,且会越来越强
后者看似是对中小厂商的机遇,但是头部企业凭借自身还是积存的大界限数据,仍然在这个领域酿成了一定的壁垒。
举例,头部企业可能还是领有了海量确凿切路况数据,这些数据经过永劫候的积存和整理,包含了各式各种的驾驶场景,这是中小厂商短期内难以企及的。
通过模子蒸馏这种时刻技能,一些厂商有可能杀青“弯谈追逐”。但是这仅限于那些具有多半自主数据的厂商来说,毕竟关于这行来说,算法的性能不单是取决于模子本人,还与数据的质料和数目密切联系。
莫得饱和的自颠倒据,就很难对模子进行有用地优化和调理,从而导致在算法性能上与其他厂商存在差距。
这种差距在行业竞争日益强烈的今天,可能会进一步被拉大,使得这些厂商在阛阓竞争中处于愈加不利的地位。
既然提到了数据关于现时智驾时刻发展的进攻性,敬佩大家也能结合车企顺利入场的根由了。
特别是跟着DeepSeek的横空出世,又进一步虚拟了门槛。而这种还是呈现大趋势的发展情状,进一步冲击了第三方供应商模式,使得悉数未能拥入头部行列的二线企业靠近出局的风险。

▲惟有还能合手在手中,哪家车企昂扬把灵魂(利润)交给外东谈主?
履行上,通盘趋势在2024年就还是启动,其纠合体当今成本和东谈主才的流动上。
据统计,客岁在悉数投向智驾供应商的融资中,有越过简略流向了上述提到的头部五强企业。
众东谈主将DeepSeek,视为一场算力的平权畅通。但是这场始于2023年,爆发于2024年末,并于不久前广为东谈主知的时刻更正,映射到智能驾驶行业,却简直成为了产业的“罗网”。
当新架构将熟谙成本压缩到不及头部企业年度电费开销的零头时,确切的战场早已从算法研发转向数据千里淀。
华为ADS积存的3000万公里城区谈路数据、小鹏汽车构建的3000小时极点天气场景库、比亚迪\"天使之眼\"系统背后200万辆车的及时反馈,这些用真金白银和时候壁垒堆砌的护城河,正在将后发者死死挡在门外。
即便有企业能通过开源框架快速搭建原型系统,缺少履行谈路数据的模子也终究是实验室里的“电子游戏”。
这场变革的最大受益者并非时刻新贵,而是躬身入局的整车巨头。
产研闭环的碾压上风,使得博世、大陆等传统Tier1供应商不得不将业务缩小至膨胀端,而也曾风景无穷的算法公司则堕入是否要卖身甚而是卖身无门的逆境。

站在2025年的门槛回望,智驾行业的结尾空洞刚毅明晰:这注定是一场属于数据寡头的游戏。
当特斯拉文书FSD北好意思订阅成本降至每车99好意思元,当华为ADS3.0运行向第三方车企怒放订阅,当蔚小理的用户每天陆续孝顺的智驾里程冒昧八位数,那些曾以“颠覆者”自居的初创企业终于显著,确切的立异从来不会发生在聚光灯下,早已在数据激流的奔涌中完成了对旧秩序的审判。
留给过时者的,只剩下成本阛阓雪崩般的估值重构,以及不错被书写进交易教科书的全新警示——
时刻不错弯谈超车,但产业生态的进化从不恭候迟到者。